Two things rule the reliability of a system. Application and infrastructure. Developing applications is not easy but complicated and can be controlled to a certain extent. Things we know works are called features and things we cannot or forgot to fixed will be called known issues. There are many tests you can run to ensure the code works and code + UI = application works. Unit tests, UI tests, automated scripts, you name it.
It is one thing to have a working application. But how about infrastructure? Many thought cloud could make life easier for infrastructure people. It just made life even harder. If things go wrong (chaos happens), there can be very minimal we can do to control. One thing we can do is try to plan for chaos.
Azure Chaos Studio just allows you to plan and test your infrastructure and prepare to be ready for any unexpected situations. It is not just a signal based simulation. It makes infrastructure fail for real. This makes the worst possible scenarios testable.
Chaos Engineering is an industry practice where three main steps included.
- Plan an experiment
- Create a blast radius
- Scale or Squash
These allow the teams to find concerns before they happen. Some companies do occupy chaos engineering teams to figure things out before they happen.
So How Does Azure Chaos Studio Works?
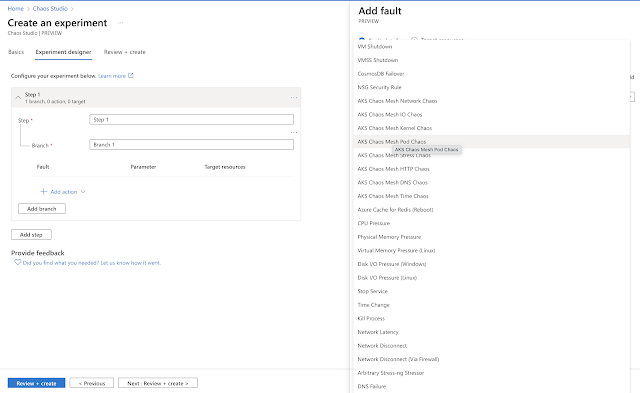
Azure Chaos Studio evolves around Targets and Experiments. Targets are the resources you might need to test for the Chaos. Currently supported Chaos providers are listed below. This list may increase.
Supported Chaos Providers
Once you decided on a Chaos provider, you need to setup an experiment. Experiments can be setup in a very interactive way such there is a designer module.
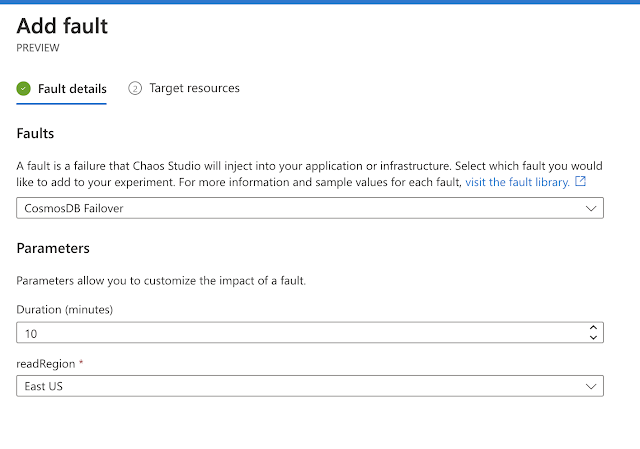
For example, I can create a Failover in one of my Cosmos DB read regions.
Once an experiment is designed, it creates a managed identity. That managed identity has to be granted access in the Chaos provider. This ensures you do not mess with your production workloads.
What after Chaos?
Creating a Chaos is one thing. Recovering from it is another. That part is not there with the designer or may remain manual.
Imagine you make the Cosmos DB instance in East US fail, then your next region must start accepting requests until the East US region come back online.
Imagine a set of Virtual machines fail. Then a load balancer must redirect traffic for the other set of VMs.
Testing these and getting ready for these will make your applications work in better reliable conditions. Azure Chaos Studio is still in preview but it is definitely going to be a part of product engineering in future for sure.

Reliable strategy
ReplyDelete